

 摘要:
...
摘要:
... 1月9日,上海人工智能实验室(上海AI实验室)联合大模型语料数据联盟成员发布了“万卷·丝路”多语言预训练语料库,为多语言大模型训练提供高质量数据支撑。
添加微信好友, 获取更多信息
复制微信号
随着共建“一带一路”进入高质量发展新阶段,科技创新与合作将在其中发挥更关键的作用。上海AI实验室通过研发先进数据智能技术,提供多语言语料库等举措,探索以人工智能赋能高质量共建“一带一路”。
“万卷·丝路”首期开源了包含泰、俄、阿、韩、越等五个语种的语料,总规模超1.2TB(单语种均超过150GB),Token总数超过300B,涵盖使用上述语种国家地区的生活、百科、文化、新闻等七大领域数据。
数据是人工智能重要的基础设施,数据质量是决定人工智能应用能力的关键因素之一。作为综合性文本语料库,“万卷·丝路”采集了多个国家地区的网络公开信息、文献、专利等资料,数据总规模超1.2TB,Token总数超过300B(300 billion),处于国际领先水平。首期开源的语料库主要由泰语、俄语、阿拉伯语、韩语和越南语5个子集构成,每个子集的数据规模均超过150GB。
基于“书生·浦语”智能标签分类体系,研究团队将每个语料子集细分为7个大类和32个小类,覆盖历史、政治、文化、房产、购物、天气、餐饮、百科、专业知识等多类具有语言所在地特征内容,便于研究者根据具体需求检索数据,并可适应不同研究领域多样化需求。

“万卷·丝路”语料库子集分类(共计7个大类、32个小类,图表中仅展示了部分标签)
“万卷·丝路”语料库通过专家人工标注,确立了包含七个维度的文本数据质量评估体系,从完整性、有效性、可理解性、流畅性、相关性、相似性和安全性等方面保障数据的高标准与高质量。
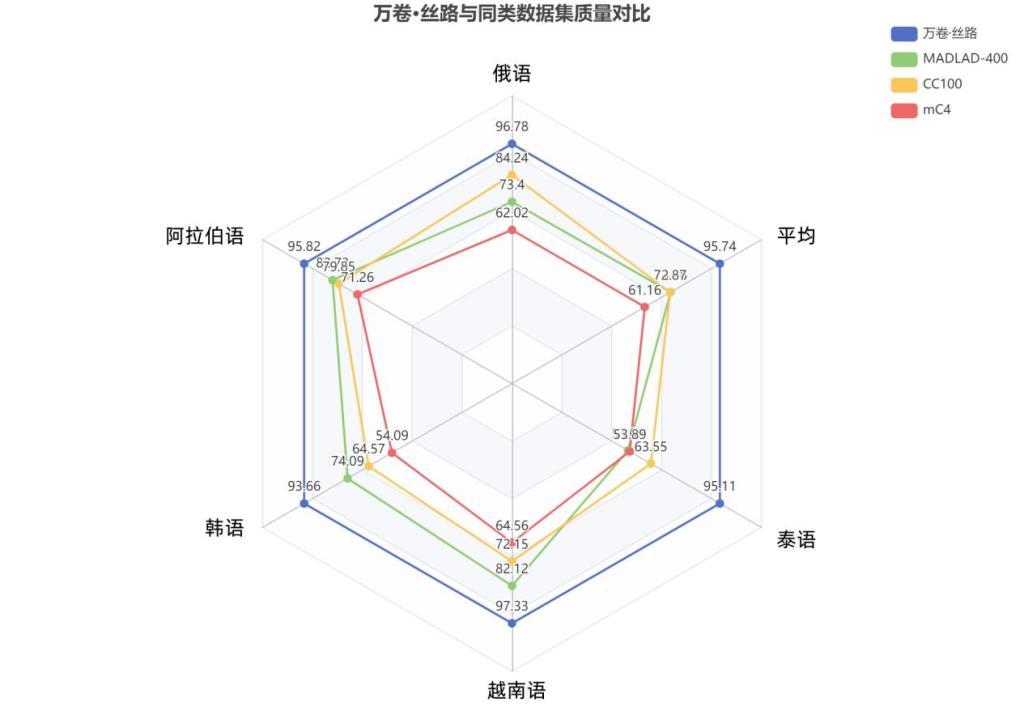
通过使用基于大语言模型的数据质量评估开源工具——Dingo(https://github.com/DataEval/dingo),研究团队从多维度对“万卷·丝路”的数据质量进行了全面评估。结果表明,其五个子集均获得优异的综合评分。
大模型语料数据联盟由上海人工智能实验室联合中央广播电视总台、人民网、国家气象中心、中国科学技术信息研究所、上海报业集团、上海文广集团等10家单位联合发起。










还没有评论,来说两句吧...